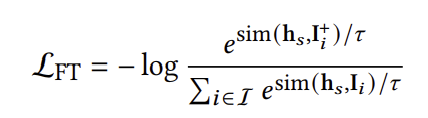Text Is All You Need (Recformer)
‘Text Is All You Need: Learning Language Representations for Sequential Recommendation’ 논문을 간단하게 요약 정리한 글입니다.
Introduction
전통적인 sequential recommendation은 아이템을 ID로 변환시키고 이에 해당하는 임베딩을 두어 학습하는 방식을 사용한다. 이러한 방식은 cold-start item을 표현하는 데에 한계가 있으며, 기존 데이터셋에서 학습한 지식을 활용해 새로운 데이터셋에서 추천을 진행하기도 어렵다.
따라서 transferable한 추천 시스템을 개발하려는 연구들이 여럿 있었으며, 대표적으로 제목 및 세부 설명과 같은 텍스트 정보들로 아이템을 표현하는 시도가 존재했다. 기본적인 방식은 사전학습된 언어 모델을 사용해 해당 아이템의 텍스트 표현을 얻어내고 텍스트 표현을 아이템 표현으로 변환하는 모델을 두는 것이다. 다만 이러한 방법론에는 3가지 한계가 있다.
- 사전 학습된 언어모델은 범용적인 corpus에서 학습되었기에 domain-specific한 데이터에 대한 표현이 부족하다.
- 언어모델은 문장 단위의 광범위한 문맥만을 제공해 줄 뿐, 추천에 있어서 중요한 attribute를 학습하는 등과 같은 세부적인 유저 성향은 고려하지 않는다.
- 언어 모델과 추천 모델은 서로 독립적으로 학습되기에, joint training을 통한 발전 가능성이 남아있다.
Methodology
따라서 저자들은 이러한 문제들을 해결하는 새로운 모델인 Recformer를 제안한다.
Problem Setup and Formulation
Recformer에서 아이템들은 기본적으로 ID에 따른 임베딩이 아닌 오직 텍스트만으로 표현된다. 각 아이템 $i$는 사전 \(D_i = \{(k_1, v_1), (k_2, v_2), ..., (k_m, v_m)\}\)를 가지며, 각 key, value는 여러 개의 단어들로 구성된다고 하자. 그렇다면 item $i$의 텍스트 표현은 사전을 일렬로 이어 붙인 \(T_i = \{k_1, v_1, k_2, v_2, ..., k_m, v_m\}\)이 될 것이다.
예를 들어 맥북 프로의 경우, {title: ‘MacBook Pro’, brand: ‘Apple’, category: ‘Laptop’, …}과 같은 사전을 가질 것이며, 텍스트 표현은 이를 이어 붙인 [‘title’, ‘MacBook’, ‘Pro’, ‘brand’, ‘Apple’, ‘category’, ‘Laptop’, …]가 된다.
Recformer
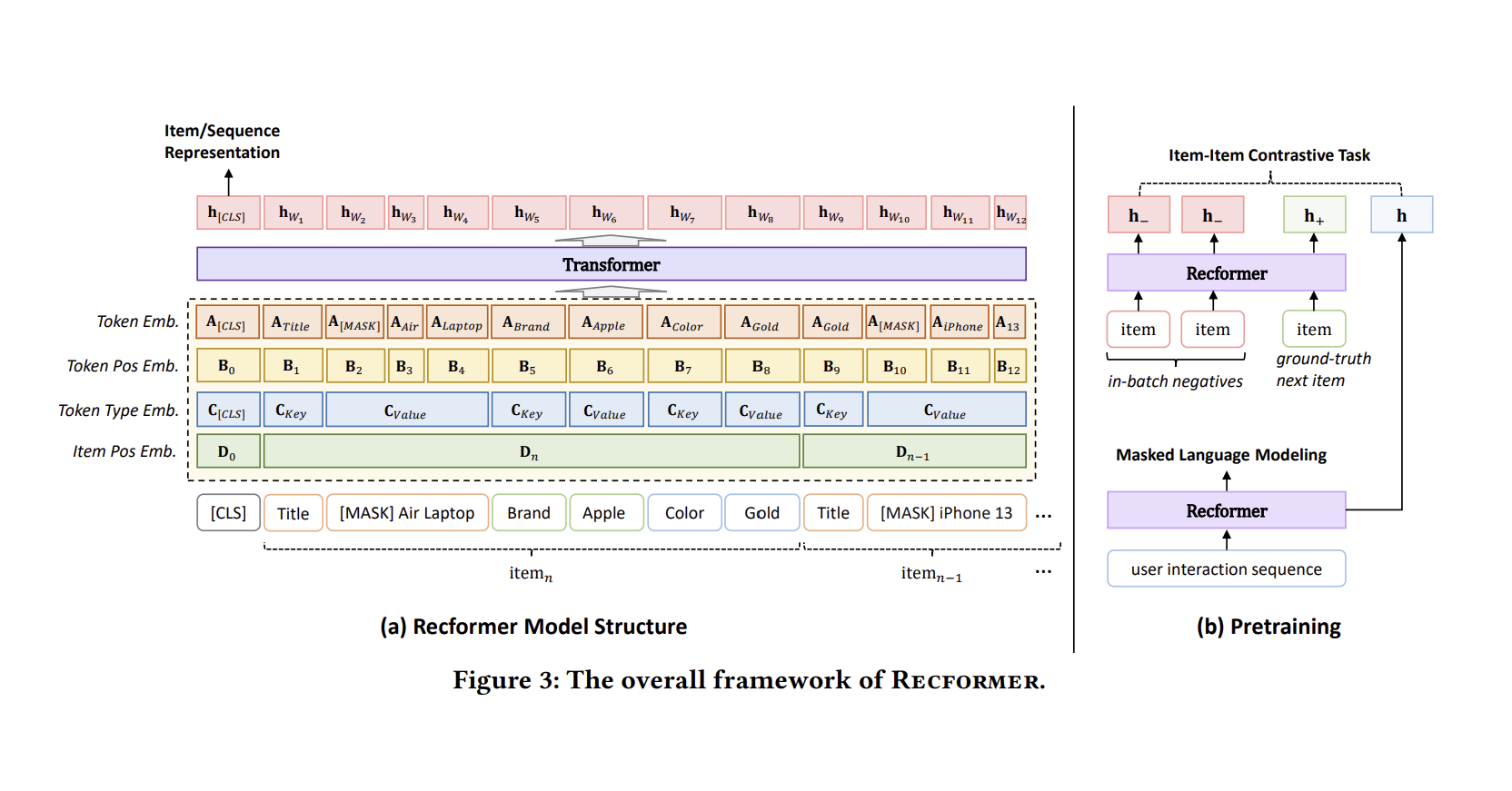
위 그림은 Recformer의 구조를 나타낸다. Recformer는 기본적으로 Longformer를 기반으로 두고 있지만 이는 오직 계산 효율성을 위한 것으로, BERT나 BigBird와 같은 구조도 사용 가능하다.
Model Inputs
모델은 유저의 interaction sequence \(s = \{i_1, i_2, ..., i_n\}\)를 입력을 받는다. 다만 가장 최근에 상호작용한 아이템이 중요하다는 가정하에 sequence를 역순으로 정렬한다. 그리고 특별한 토큰인 [CLS]를 sequence의 앞에 붙인다. 최종적인 모델의 입력은 아래와 같이 표현된다.
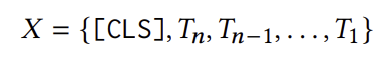
이때 $T_i$는 위에서 설명했던 아이템 $i$의 텍스트 표현이다.
Embedding Layer
Recformer는 아래의 4가지 임베딩을 사용한다.
Token embedding
토큰 자체를 표현하는 임베딩이다.Token position embedding
Sequence 내 토큰의 위치를 표현하는 임베딩이다.Token type embedding
토큰의 타입에 해당하는 임베딩이다.
토큰이 [CLS]인지, key인지, value인지를 구분하기 위해 사용된다.Item position embedding
Sequence 내 아이템의 위치를 표현하는 임베딩이다.
이러한 임베딩은 모두 학습 가능하며, 최종 임베딩은 아래와 같이 모든 임베딩을 더하고 normalization을 거침으로써 얻어진다.
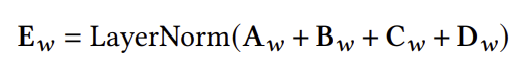
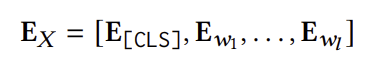
Item or Sequence Representation
Recformer는 위에서 구한 임베딩의 sequence를 Longformer에 통과시켜 유저의 최종 표현을 얻어낸다. 이는 아래와 같이 표현되며, $h_{[CLS]}$가 바로 유저의 최종 표현이 된다.
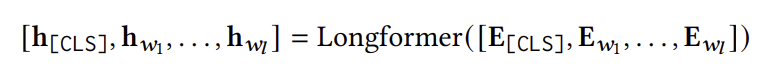
유의할 점은 나머지 토큰들은 longformer 구조에 따라 local windowed attention을 사용하지만 [CLS] 토큰은 전역적인 attention이 존재한다는 것이다.
나아가 item $i$의 표현은 아래와 같이 아이템 한 개만 존재하는 sequence를 Recformer에 통과시킨 결과로 얻어진다.
Prediction
위 방식으로 유저 표현과 아이템 표현을 얻어냈다면, 최종적인 예측을 위해 유저와 아이템의 코사인 유사도를 계산한다. 이렇게 구한 유사도를 바탕으로, Recformer는 유저 표현과 가장 유사한 아이템을 유저가 다음으로 소비할 아이템으로 예측한다.
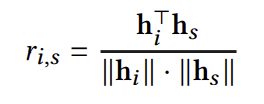
Learning Framework
Reformer의 학습은 크게 pre-training과 two-stage finetuning으로 나뉜다.
Pre-training
1. Masked Language Modeling
Recformer는 BERT와 같은 방식으로 MLM을 수행한다. 구체적으로, Recformer는 15%의 토큰을 학습할 토큰으로 지정하고 이 중 80%는 [MASK]로, 10%는 랜덤한 토큰으로, 10%는 그대로 둔다. 그리고 모델을 통과시킨 뒤 변형하기 이전의 올바른 토큰을 예측하도록 학습한다. MLM loss는 아래와 같이 계산된다.
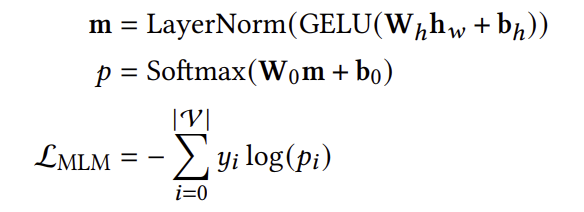
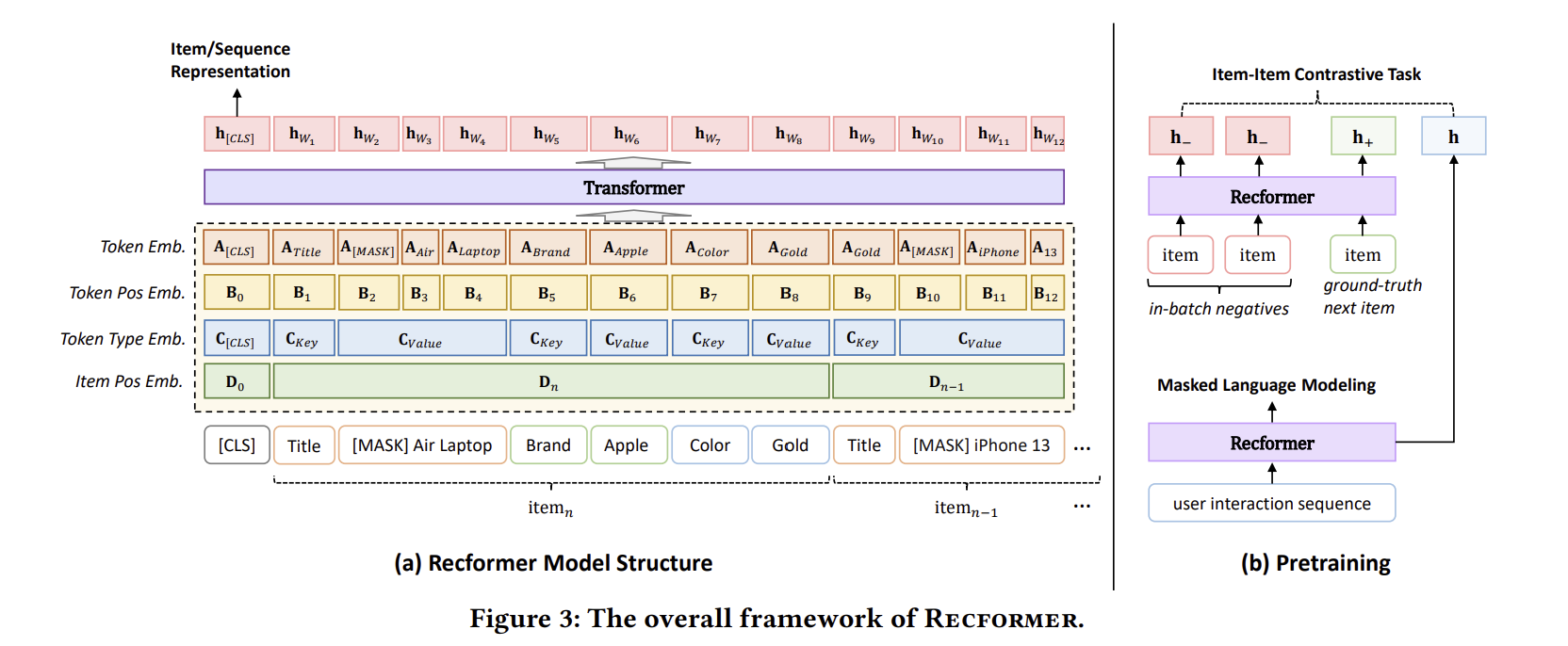
2. Item-Item Constrastive Learning
Recformer는 나아가 다음 소비할 아이템인 ground-truth item을 positive sample로 두고, batch 내 다른 positive sample을 negative sample로 두어 item-item contrastive learning을 수행한다. Negative sample을 직접 샘플링하지 않고 다른 positive sample을 negative sample로 간주하는 이유는 sample의 representation을 구하려면 모델을 다시 통과시켜야 해 계산적으로 부담이 크기 때문이다.
Sampling을 마친 후, contrastive loss는 아래와 같이 계산된다.
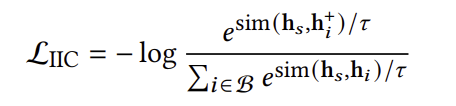
3. Final Loss
위 두가지 pretraining loss를 합친 최종 loss는 아래와 같이 계산된다.
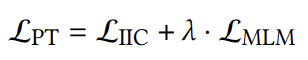
이때 $\lambda$는 두 loss의 상대적인 중요도를 나타내는 하이퍼파라미터이다.
Two-Stage Finetuning
Finetuning은 크게 두 단계로 나뉜다. Stage 1은 아이템 표현 행렬 $I$이 매 epoch마다 업데이트되면서 모델이 학습되고, Stage 2는 $I$를 고정시킨 채로 학습한다. 굳이 이런 식으로 두 단계로 나눈 이유는 모델과 아이템 표현을 한꺼번에 최적화시키는 것보다 Stage 1에서 좋은 아이템 표현을 학습한 뒤, Stage 2에서 고정된 아이템 표현을 바탕으로 학습하는 것이 모델을 더 세밀하게 개선할 수 있기 때문이다.
최종적인 학습은 아래와 같이 item-item contrastive learning을 통해 이루어진다. Pre-training과 다른 점은 positive sample을 제외한 나머지 모든 아이템을 negative sample로 둔다는 것이다.