Wide & Deep Learning for Recommender Systems
‘Wide & Deep Learning for Recommender Systems’ 논문을 간단하게 요약 정리한 글입니다.
Abstract
비선형적인 feature transformation을 적용해 ‘wide’한 feature를 사용하는 linear model은 효과적이고 interpretable하지만, 일반화 성능이 떨어진다. 반면, ‘deep’ neural network는 이러한 feature engineering 없이 학습하여 뛰어난 일반화 성능을 보이지만, over-generalize되어 관련성이 낮은 추천을 하곤 한다. 저자들은 이러한 두 모델을 결합한 ‘Wide & Deep learning’ 모델을 제안한다.
The Wide Component
Wide component는 단순한 linear model로, $y = w^Tx + b$와 같이 표현된다. 이때 feature $x$는 raw input feature들과 feature transformation을 통해 생성된 cross-product feature들을 포함한다. 이러한 cross-product feature들은 아래와 같은 식으로 생성된다.
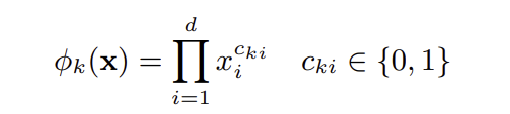
예를 들어, gender=female이면서 동시에 language=english 이어야만 1이고 그 외의 경우에는 0인 cross-product feature AND(gender=female, language=english)를 생성할 수 있을 것이다. 이러한 cross-product feature들을 추가함으로써 feature들 간의 interaction을 포착할 수 있을 뿐만 아니라 모델에 non-linearity를 추가할 수 있다.
The Deep Component
Deep component는 feed-forward neural network로, wide component와 달리 feature engineering 없이 학습된다. 다만 입력이 sparse하고 high-dimensional하기 때문에 embedding layer를 통과하여 학습가능한 dense embedding으로 변환된다. 이후 이 embedding vector들은 여러개의 hidden layer를 거친다. 이를 수식으로 표현하면 아래와 같다.
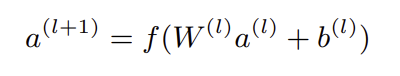
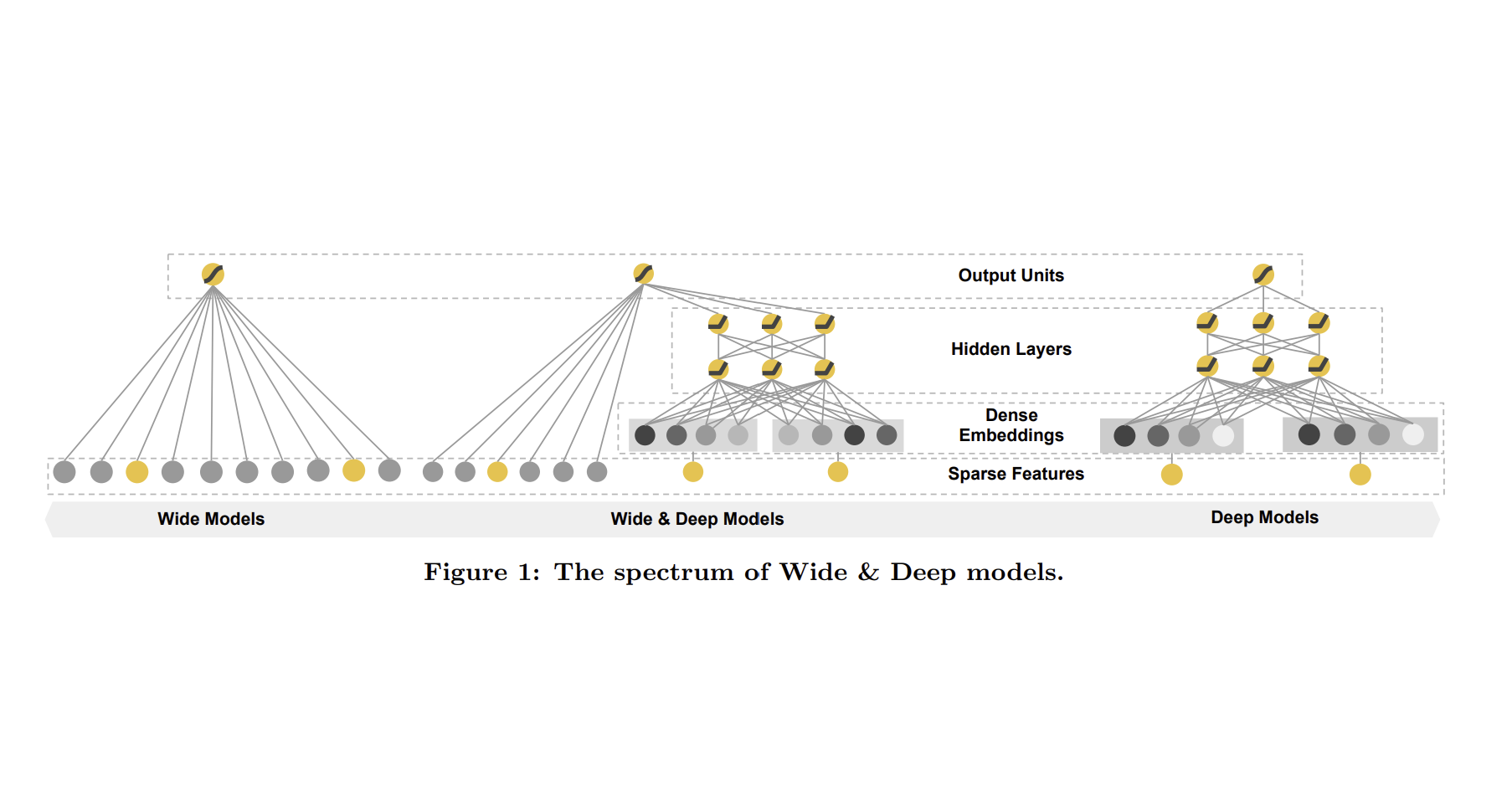
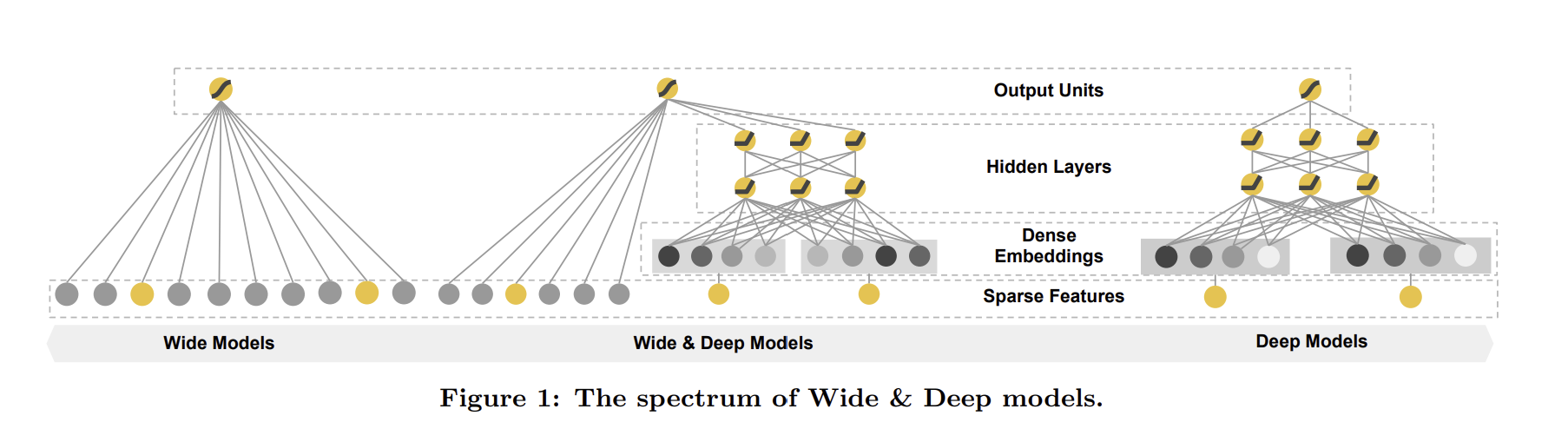
Joint Training of Wide & Deep Models
Wide & Deep learning 모델은 위의 두 모델을 결합한 형태로, wide component와 deep component를 동시에 학습시킨다. 동시에 학습, 즉 joint training은 ensemble과는 전혀 다른 개념이다. Ensemble에서는 각 모델을 따로 학습시킨 후 합치는 반면, joint training에서는 한 학습에 대해 두 모델의 파라미터를 동시에 업데이트한다. Model size의 관점에서도 차이점이 존재한다. Ensemble은 각 모델이 독립적으로 예측해야 하기에 모델의 크기가 크지만, joint training은 두 모델이 서로의 예측을 보완하고자 하기에 각각의 모델의 크기가 작다.
최종적으로 Wide & Deep learning 모델은 아래와 같이 정의된다.